 Code Wolfpack
Code WolfpackGood morning and Merry Christmas, Code Wolfpack! (And a special good morning to the folks reading this from the .NET Advent Calendar!) For those who have followed along with the Code Wolfpack series on Twitch, you’ll know there has been quite a gulf between the broadcasts and the posts on here. This is no coincidence — I have been working very hard on getting things put together for the Decentralizing the Database series, which we’re kicking off today with this special edition post.
Allow me to re-introduce myself
When I first started developing Howler (a chat client similar to Discord, Slack or Matrix) for the Code Wolfpack series, it was really useful to show design patterns which reflected utility in a variety of deployment scenarios, ranging from traditional centralized deployments (Discord/Slack), federated (Matrix) to fully peer-to-peer. We designed data models which lent well to the latter, but had not yet dove into what it would take to build the underlying backing services to facilitate such an approach. As we neared the completion of the centralized and federated versions of Howler, it became clear that E2EE and the peer-to-peer version desired for the platform would be fraught with difficulty in the IaaS context, for a number of reasons:
- External Forces - Cloud providers are alarmingly hostile to hosts of services which enable freedom of speech — this has been proven by platforms that have either been coerced by cloud providers to restrict content and/or been removed entirely from those providers, leaving the services scrambling to build out their own data centers.
- Trusting Trust - Even if the service itself does not retain data beyond that which is necessary to make the service functional, cloud providers are not beholden to the same standard, and can and do collect data around the use of their own services which could provide at a minimum, metadata which could be used to identify users/deanonymize them when they did not consent to doing so, and further if the issuance of certificates is managed by the same provider, seamlessly insert an alternative one at the behest of a state level actor.
- Infectious Design - To provide a decentralized offering alongside the centralized would still require significant build-out distinct from the latter’s present design, and ultimately “infect” the centralized platform to the point the distinction is moot.
This required a lot of soul searching — Howler was initially intended to be for educational purposes, but the pressures in the world made it clear that there was also a tremendous need for a service which can enable safe, secure, private communication amongst groups at the scale of Discord without the serious issues Discord has. Matrix, for all its fanfare finds itself frequently hamstrung by its design causing massive version/feature fragmentation, confusing setup and deployment, and flexibility ad nauseum, not to mention its group encryption (Megolm) not preserving forward secrecy like Signal’s Double-Ratchet protocol provided for the two-party case, and true decentralization still not being supported. Thus, the Howler project pivoted from being strictly an educational approach to systems design and into being a real product which serves an emerging market need — but not to be one to forego its genesis, Howler remains open source, and is developed out in the open on weekly streams (returning after the New Year).
This next section is going to lean very heavy on terms in cryptography. If you want to skip to the more general developer-oriented topic at hand, feel free to jump down to the “Back to .NET” section.
That’s great, it starts with a new SHAKE, cuckoos, stakes and multibranes
Needless to say, when we venture into the realm of multi-party private communication under adversarial conditions, the lexicon rapidly elevates to where it feels more to new and old developers alike as if one is peering into a taxonomic guide to Lovecraftian cosmic entities and finding their eyes turn black and they are suddenly repeating incantations summoning forth Cthulhu. I will try to make this as plain as possible to understand when we dive into these specific topics, but I will also try to keep these things as separated from the Howler service as possible. This first part could not avoid it, as it relates to the magic of how these concepts will impact our design choices.
As I mentioned, it was no coincidence that Howler’s data design was built around the notion of being amenable to being hosted on decentralized platforms — identifiers are deterministic and immutable, message history linkage for reply threading is deniable, and search indexability is verifiably pre-computed at the client level, permitting oblivious accumulator schemes for fast blind retrieval from external hosts. Configuration was purely a singular document store, fully segregated from the user information beyond a unique identifier for retrieval, albeit one using the user id, not that this was mandatory for the design to function. But there are deficits in the current state of the art in cryptography and decentralized trustless systems to provide what Howler needs. Let’s break it down, because each item is a lot to unpack:
Fast, secure multi-party communication with perfect forward secrecy
Signal’s Double-Ratchet Protocol answers the two-party case, but the current solution for multi-party configurations has severe tradeoffs that compromise most of the security benefits Double-Ratchet provides. These tradeoffs include a loss of future and perfect forward secrecy. Not to throw up my arms and reluctantly choose either an expensive multi-party X3DH ratchet (i.e. n-1 rounds of messages to create a new ratchet, where n is the number of users in a group) or the non-starter of Megolm’s tradeoffs, I have created a new protocol, leveraging the recent discoveries in trustless distributed key generation schemes with an adversarial majority as a precursor ratchet that provides keys for the Double-Ratchet Protocol, generalizing to what I am calling the Triple-Ratchet Protocol (publication to follow: Secure Multi-party Communication with Perfect Forward Secrecy). To support WebCrypto interfaces in the browser and greater hardware enclave compatibility, I have amended the protocol to use general elliptic curve cryptographic primitives: ECDSA, and ECDH.
Decentralized trustless private hypergraph database with oblivious queryability
The other downside to Signal and Matrix is the aforementioned metadata problem. Some approaches try to simply leverage indirection by embedding their service in Tor as a hidden service, despite Tor being effectively compromised. Message retention is also predicated on availability of ratchet state, and group size changes require transfering the ratchet state on addition for historic access to messages. Message ordering in the Megolm case is also not guaranteed, with a fractured and somewhat mutable chat state. In the Triple-Ratchet approach, ordering is preserved, but the ratchet state transference issue is still retained, and thus we must introduce a protocol for message storage which enables oblivious historic retrieval and queryability of message history without a loss to future and perfect forward secrecy. In upcoming parts of this series, I will present concept by concept the techniques which enable this, ultimately creating a CQL-compatible (per-clique) version of this database.
Decentralized Identity
As we discussed in our session on QR Authentication, key exchange itself has an adversarial component that requires a separate channel for authentication. We solved for this in the QR Code case by presenting a post-exchange value derived from the agreed key the user must confirm matches on both devices. Because the user is on both sides of this exchange, they are themselves the separate channel, via their eyes (not to mention this being predicated on trusting the software or hardware itself is not compromised, but there are significantly greater problems at hand if this is the case). Thankfully, due to the emerging world of cryptocurrencies, self-governed identities have already seen a lot of exploration, and so we will simply integrate with a number of cryptocurrencies’ common wallet APIs (starting with Ethereum/EVM-compatible and Solana) to provide this DID infrastructure.
Back to .NET
So that was a lot to take in (and it doesn’t even include all the nitty gritty details!), but with the protocol side of things squared away, we can focus on the crux of the article: Enabling the peer-to-peer communication required to support this approach with SignalR.
What is SignalR?
In short, it is a library that makes it very simple to provide real-time communication between a client and server. By adding SignalR middleware to your ASP.NET Core application, you can support websockets (and very graceful fallbacks to other transport mechanisms) with the Hub metaphor as intuitively as you build APIs with the built-in Controller/Action semantics for RESTful interfaces. Not to leave the transport negotiation as an implementation detail on the client side, there is also an accompanying library for Javascript/Typescript. But it doesn’t stop there — consider the trivial example of a basic unauthenticated non-durable chat app: no channels, nothing saved, just a user id and text for each message for those around to receive it. Once you reach the limit of a single server, the obvious answer is to scale horizontally, which would then lend towards thinking about some kind of storage to share between servers, even if just using Redis, or maybe each server will connect to each other and shuttle messages back and forth. An experienced engineer may notice this is starting to sound like a message bus. The good news is SignalR happens to support the pattern outright, with the HubLiftetimeManager abstract class forming the foundation on which a variety of bus implementations may be used. Built into SignalR, you can use Redis and Azure Service Bus as the backplane. This makes it extremely easy to scale out your messaging infrastructure so that if in this contrived example, one client connects to server A, and another to server B, both parties will be assured to see all messages from each server.
Practically Speaking
So how do you build a Hub? Extend from the Hub class, and you will have access to the protected properties which streamline the pub/sub mechanics:
public class ExampleHub : Hub
{
private ILogger<ExampleHub> _logger;
public ExampleHub(ILogger<ExampleHub> logger)
{
this._logger = logger;
}
public async Task JoinChannel(string channelName)
{
await this.Groups.AddToGroupAsync(
this.Context.ConnectionId,
channelName);
await this.Clients.Group(channelName)
.SendAsync("UserJoin", channelName, this.Context.ConnectionId);
await this.Clients.Caller.SendAsync(
"JoinChannelSuccess",
channelName);
}
public async Task SendMessage(string channelName, string message)
{
await this.Clients.Group(channelName).SendAsync(
"ReceiveMessage",
channelName,
this.Context.ConnectionId,
message);
}
public async Task LeaveChannel(string channelName)
{
await this.Groups.RemoveFromGroupAsync(
this.Context.ConnectionId,
channelName);
await this.Clients.Group(channelName)
.SendAsync("UserLeave", channelName, this.Context.ConnectionId);
await this.Clients.Caller.SendAsync(
"LeaveChannelSuccess",
channelName);
}
}Note that this simple example actually goes one step farther than the contrived example, adding channels as a mode of separation (obviously without checking channel membership on sends, but joining is unauthenticated anyway). Registering the Hub to be available in Startup.cs is also straightforward:
// Amend your existing UseEndpoints to include your hub:
app.UseEndpoints(endpoints =>
{
endpoints.MapControllers();
endpoints.MapHub<ExampleHub>("/example");
});On the client side, add @microsoft/signalr to your package.json, and on import, connecting and handling messages/sending is this easy:
let connection = new signalR.HubConnectionBuilder()
.withAutomaticReconnect()
.withUrl(serverUrl + "/example").build();
connection.start();
connection.on("JoinChannelSuccess", (channelName) => {
console.log("joined " + channelName);
});
connection.on("LeaveChannelSuccess", (channelName) => {
console.log("left " + channelName);
});
connection.on("UserJoin", (channelName, userId) => {
console.log("[" + channelName + "] @" + userId + " joined");
});
connection.on("UserLeave", (channelName, userId) => {
console.log("[" + channelName + "] @" + userId + " left");
});
connection.on("ReceiveMessage", (channelName, userId, message) => {
console.log("[" + channelName + "] @" + userId + ": " + message);
});
function sendMessage(channelName, message) {
connection.send("SendMessage", channelName, message);
}with that little snippet, you are immediately connected to the hub, handle all messages, and can send messages. Reconnection has sensible defaults in place (this is configurable), and authorization is pretty easy to wire up. Beautiful.
Howler and SignalR
In the federated version of Howler, we had to maintain connectivity to each logical server a user wants to participate in. Let’s revisit how that is wired up. On the UI Client side, we track state of individual federated core services connections as a map of server IDs to connection state with Redux:
export interface ServersState {
authToken: string;
servers: { [serverId: string]: ConnectionInfoState };
lastRefreshedServerId: string | null;
isLoading: boolean;
}
export interface ConnectionInfoState {
isConnecting: boolean;
connection?: signalR.HubConnection;
token: string;
userSpaces: { [userId: string]: string[] };
error?: string;
}And these connections are maintained via Sagas:
function* handleServerTokenRequest(request: RequestServerTokenAction) {
let state: ServersState = yield select(s => s.servers as ServersState);
if (
state.servers[request.serverId] == null ||
state.servers[request.serverId].token == null
) {
yield put({
type: 'REQUESTING_SERVER_TOKEN',
serverId: request.serverId
});
let token: string = yield call(
getServerToken(request.serverId, state.authToken)
);
yield put({
type: 'RECEIVE_SERVER_TOKEN',
serverId: request.serverId,
token
});
}
}
function* handleConnectionRequest(request: RequestConnectionAction) {
yield put({type: 'REQUESTING_CONNECTION', serverId: request.serverId});
yield handleServerTokenRequest({
type: 'REQUEST_SERVER_TOKEN',
serverId: request.serverId
});
let response: {
connection: signalR.HubConnection,
error: any
} = yield callServer(request.serverId, connect);
if (response.error != null) {
yield put({
type: 'FAILED_CONNECTION',
serverId: request.serverId,
error: response.error
});
} else {
yield put({
type: 'RECEIVE_CONNECTION',
serverId: request.serverId,
connection: response.connection
});
}
}
export const serversSagas = {
watchServerTokenRequests: function*() {
yield takeLeading('REQUEST_CONNECTION', handleConnectionRequest)
yield takeLeading('REQUEST_SERVER_TOKEN', handleServerTokenRequest)
}
};For a refresher course on Redux-Saga, take a look at our intro session where we discuss why and how you can integrate Redux-Saga into your React application.
Note the maintenance of server tokens and server connections involved (as there are also supplementary API calls that can server larger amounts of data outside of the websocket). As you could imagine, a user connected to many distinct servers (NB: In Howler, servers truly mean servers in a logical sense, whereas the Discord parlance of “server” is referred to as a Space.) would be fraught with many simultaneous websockets. This is less than ideal, but a necessary consequence of a federated design. By shifting to purely a peer-to-peer approach, our client does not need to keep a map of server connections at all, as it only has to maintain a single connection to the local SignalR server. We can remove all the connection/token state maintenance logic from the reducer, and just leave it as an API surface, closer to the ExampleHub, which is a nice simplification.
On that note of refactoring
Consider the historical architecture of centralized Howler:
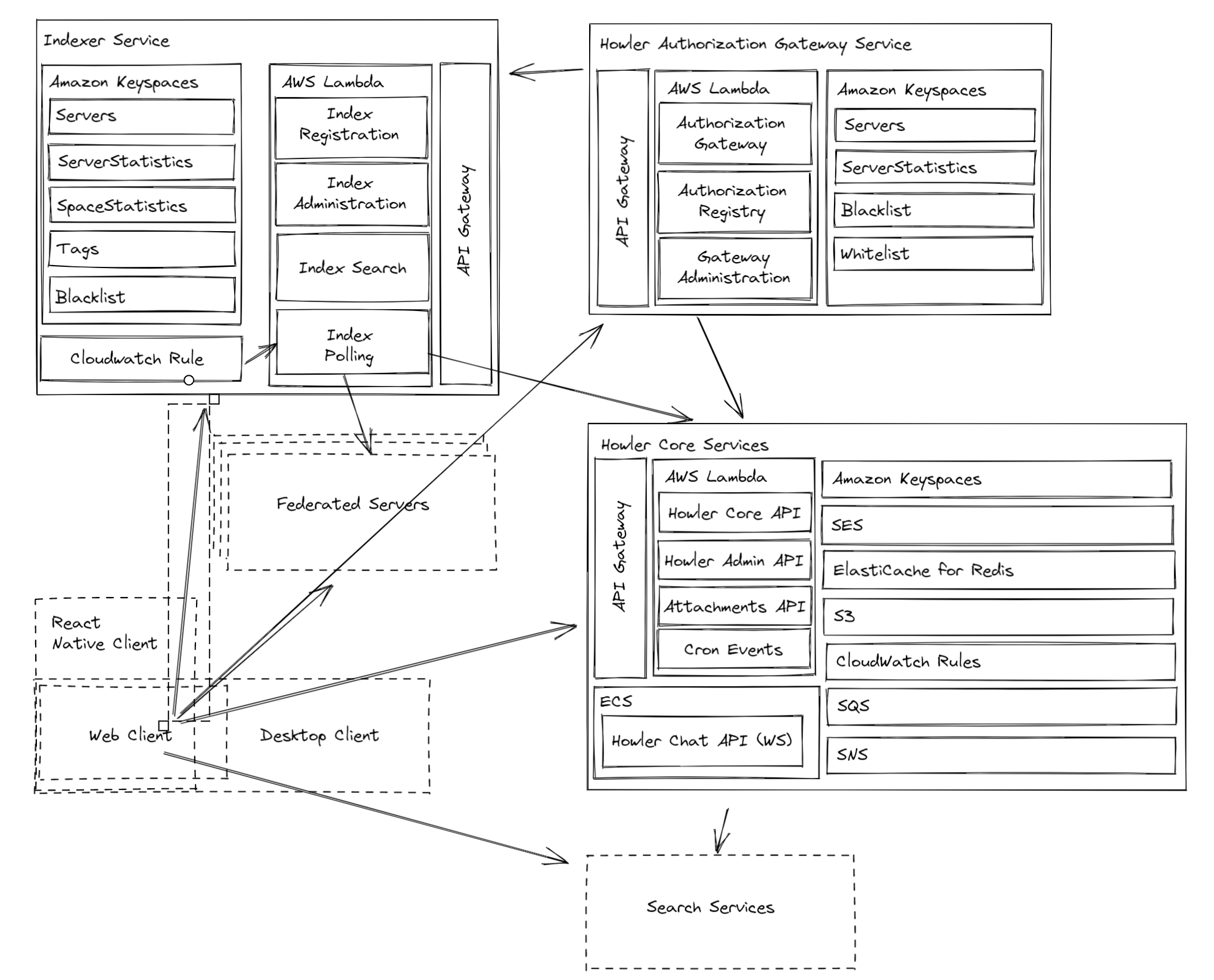
In decentralized architectures, the notion of a server is somewhat nebulous, as every peer is a server, but the logical “server” is the collective operations of each node, with their own replicated state localized for whatever interaction is required. For Howler to move into a peer-to-peer approach, we can make some adjustments to the diagram, like so:
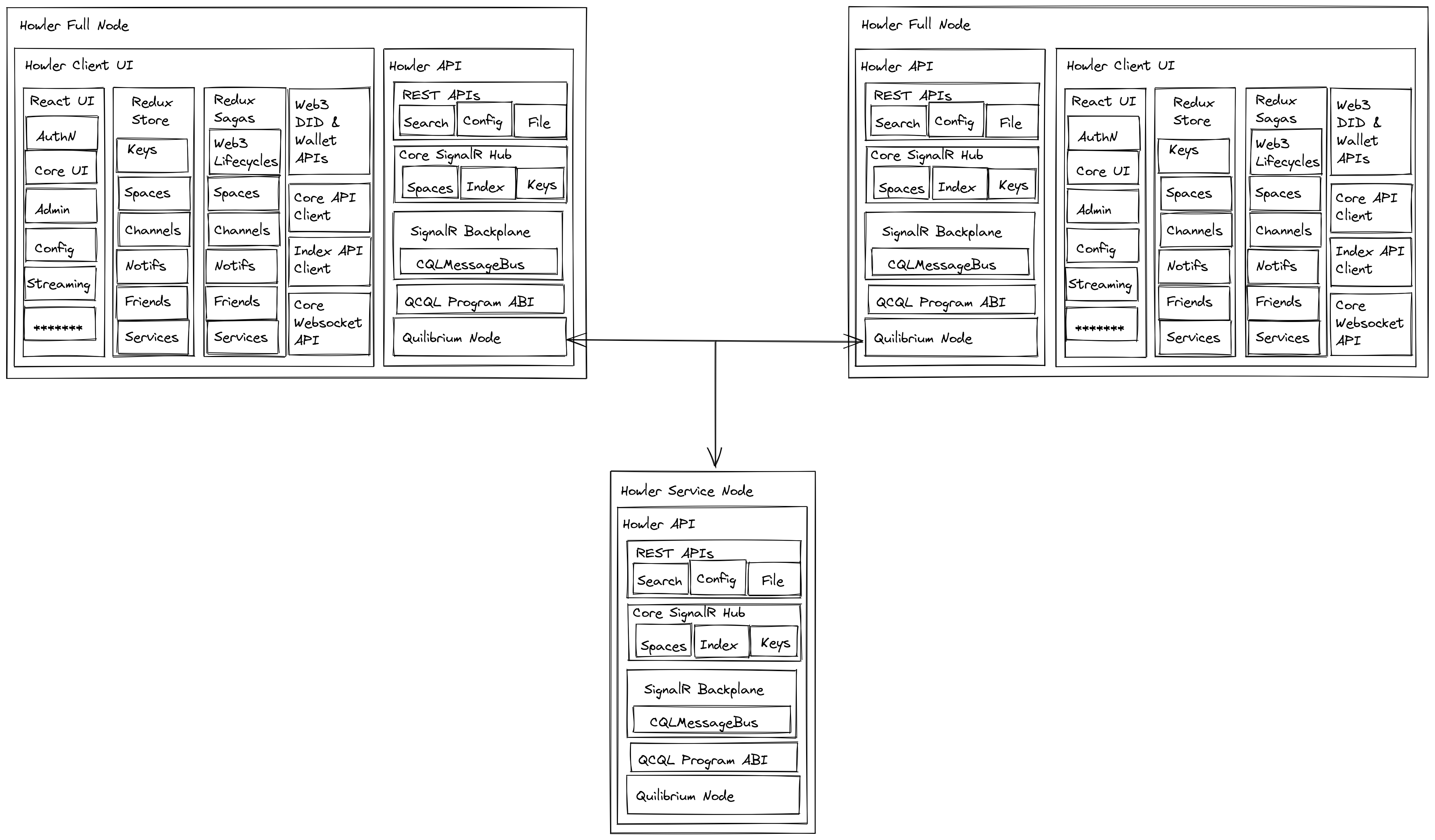
That looks a bit more complicated! Let’s break it down. Short of the DID integration needs for the UI, most of this is unchanged. So let’s focus strictly on the server layer:
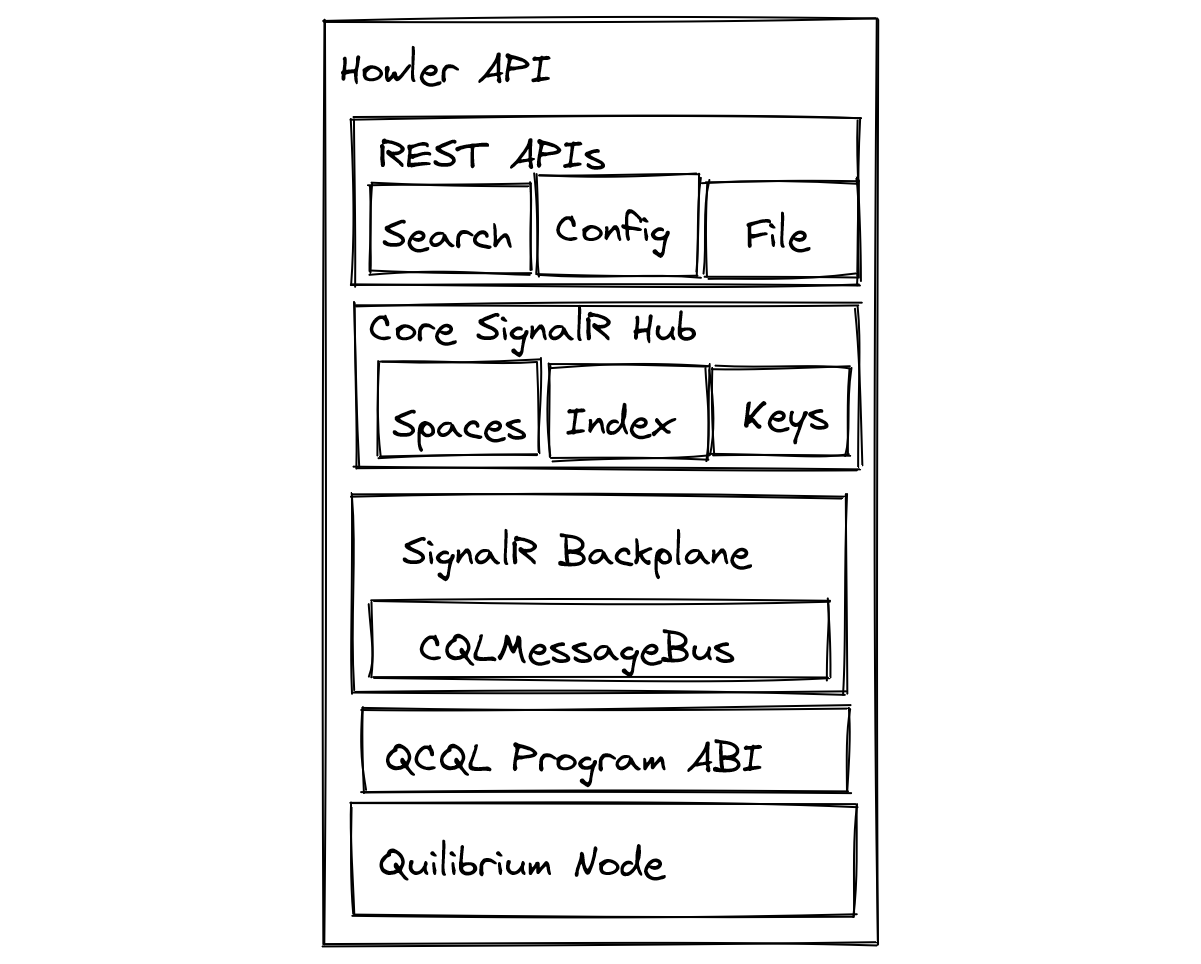
Quite a bit more manageable. There’s some new stuff! We’ll elide over the addition of the Keys hub, that will be relevant in Part 2 where we review the Triple-Ratchet Protocol implementation. That leaves us with three boxes: the SignalR Backplane, the QCQL Program ABI, and the Quilibrium Node.
You mentioned the backplane already, but what is Quilibrium? And did you bash your keyboard in the middle?
Quilibrium is a new general purpose peer to peer platform as a service. I’ll save the general PR statement for another post, but that is the key piece of “magic” that makes this approach possible. In particular, we will leverage the Quilibrium node library to provide our aforementioned hypergraph database, no different than if you were to launch an AWS Keyspaces database, except in this scenario, each node in the network is a part of the fabric that makes the database application code run. We will provide one additional enhancement, which is the application binary interface, or ABI, to present our CQL compatibility layer, allowing us to substitute this in place of our Keyspaces servers. But more about that in another post — today, we are going to treat this no differently than if we were using our Cassandra docker container like before. That’s where the backplane comes into play.
SignalR Backplanes
The built in backplanes are fantastic for deploying alongside Redis or deeply integrating with Azure, however CQL is not supported out of the box. Rather than building out a Redis compatibility ABI alongside a CQL compatibility ABI and just using the built in Redis backplane, we can simply build towards a fully-integrated future with our overall data model. As a benefit, the greater participation in the overall network will further reduce potentially fingerprintable traffic thus enhancing privacy. All done with one very simple abstract class to implement (doc comments omitted):
// Licensed to the .NET Foundation under one or more agreements.
// The .NET Foundation licenses this file to you under the MIT license.
using System.Collections.Generic;
using System.Threading;
using System.Threading.Tasks;
namespace Microsoft.AspNetCore.SignalR;
/// <summary>
/// A lifetime manager abstraction for <see cref="Hub"/> instances.
/// </summary>
public abstract class HubLifetimeManager<THub> where THub : Hub
{
// Called by the framework and not something we'd cancel, so it doesn't
// take a cancellation token
public abstract Task OnConnectedAsync(HubConnectionContext connection);
// Called by the framework and not something we'd cancel, so it doesn't
// take a cancellation token
public abstract Task OnDisconnectedAsync(HubConnectionContext connection);
public abstract Task SendAllAsync(
string methodName,
object?[] args,
CancellationToken cancellationToken = default);
public abstract Task SendAllExceptAsync(
string methodName,
object?[] args,
IReadOnlyList<string> excludedConnectionIds,
CancellationToken cancellationToken = default);
public abstract Task SendConnectionAsync(
string connectionId,
string methodName,
object?[] args,
CancellationToken cancellationToken = default);
public abstract Task SendConnectionsAsync(
IReadOnlyList<string> connectionIds,
string methodName,
object?[] args,
CancellationToken cancellationToken = default);
public abstract Task SendGroupAsync(
string groupName,
string methodName,
object?[] args,
CancellationToken cancellationToken = default);
public abstract Task SendGroupsAsync(
IReadOnlyList<string> groupNames,
string methodName,
object?[] args,
CancellationToken cancellationToken = default);
public abstract Task SendGroupExceptAsync(
string groupName,
string methodName,
object?[] args,
IReadOnlyList<string> excludedConnectionIds,
CancellationToken cancellationToken = default);
public abstract Task SendUserAsync(
string userId,
string methodName,
object?[] args,
CancellationToken cancellationToken = default);
public abstract Task SendUsersAsync(
IReadOnlyList<string> userIds,
string methodName,
object?[] args,
CancellationToken cancellationToken = default);
public abstract Task AddToGroupAsync(
string connectionId,
string groupName,
CancellationToken cancellationToken = default);
public abstract Task RemoveFromGroupAsync(
string connectionId,
string groupName,
CancellationToken cancellationToken = default);
}Of course, there’s a lot of specialized management to think about for implementing this interface well in a pattern that can scale out well. While we won’t be diving into the nuances of how our QCQL application works in this post, the detail worth noting is that a keyspace is created for every Space, and so in our case, a SignalR backplane will be need to be addressible on a per-Space basis. With that in mind, what will we do instead?
- Backplane configurability will need to be contingent on the active keyspaces to scan, one stream per keyspace
- Message composite keys will be bucketed into 100 millisecond partition keys, using
now()
To make our example a little easier to grok, we will omit the multi-Space consideration, and opt for only one stream, one keyspace. How does this play out in the schema?
CREATE TABLE "howler_messagebus"."message"(
"message_bucket_id" BIGINT,
"message_timestamp" TIMESTAMP,
"message_id" ASCII,
"payload" BLOB,
PRIMARY KEY("message_bucket_id", "message_timestamp"))By concentrating our resolution to 100ms intervals, we phase our lookbacks on retrieval to small enough increments where when on a high speed connection, messages are imperceptibly instant. If of course connectivity is hindered or slow, messages will arrive when they arrive. To avoid a poor user experience, we bake in the expectation in our use of SignalR that deliverability on the backplane is not guaranteed (although invariably it would arrive), and appropriate retrievals from the channel messages table will need to occur periodically to shore up inconsistencies.
So let’s get into the CQL version of the HubLifetimeManager constructor:
/// <summary>
/// Initializes a new instance of the
/// <see cref="CqlKeyspaceHubLifetimeManager{THub}"/> class.
/// </summary>
/// <param name="logger">
/// The injected instance of the logger.
/// </param>
/// <param name="options">
/// The <see cref="CqlOptions"/> that configures the Cassandra Session.
/// </param>
/// <param name="hubProtocolResolver">
/// The injected instance of <see cref="IHubProtocolResolver"/>, gets an
/// <see cref="IHubProtocol"/> instance to write to connections.
/// </param>
/// <param name="globalHubOptions">
/// The injected global <see cref="HubOptions"/>.
/// </param>
/// <param name="hubOptions">
/// The injected <typeparamref name="THub"/> specific options.
/// </param>
public CqlKeyspaceHubLifetimeManager(
ILogger<CqlKeyspaceHubLifetimeManager<THub>> logger,
IOptions<CqlOptions> options,
IHubProtocolResolver hubProtocolResolver,
IOptions<HubOptions>? globalHubOptions,
IOptions<HubOptions<THub>>? hubOptions)
{
this._logger = logger;
this._options = options.Value;
if (globalHubOptions != null && hubOptions != null)
{
this._handler = new CqlMessageHandler(
new DefaultHubMessageSerializer(
hubProtocolResolver,
globalHubOptions.Value.SupportedProtocols,
hubOptions.Value.SupportedProtocols));
}
else
{
var supportedProtocols = hubProtocolResolver.AllProtocols
.Select(p => p.Name).ToList();
this._handler = new CqlMessageHandler(
new DefaultHubMessageSerializer(
hubProtocolResolver,
supportedProtocols,
null));
}
this._session = this._options.CreateSession();
this.StartSubscriberAsync(this._options.Interval, this._options.Tolerance);
}You can see a unique CqlMessageHandler class, it is basically a CQL select/insert/delete statement generator. The DefaultHubMessageSerializer is an internal of SignalR, serializing all message formats supported by the Hub back to the client. StartSubscriberAsync? We’ll get to that momentarily. The rest of this is going to get very boilerplate following a pattern, so let’s hone in on a couple of examples:
/// <inheritdoc />
public override Task AddToGroupAsync(
string connectionId,
string groupName,
CancellationToken cancellationToken = default)
{
if (connectionId == null)
{
throw new ArgumentNullException(nameof(connectionId));
}
if (groupName == null)
{
throw new ArgumentNullException(nameof(groupName));
}
var connection = this._connections[connectionId];
if (connection != null)
{
// short circuit if connection is on this server
return this.AddGroupAsyncCore(connection, groupName);
}
return this.SendGroupActionAsync(
connectionId,
groupName,
"add");
}
private async Task SendGroupActionAsync(
string connectionId,
string groupName,
string action)
{
var message = this._handler.WriteGroupCommand(
this._serverName,
action,
groupName,
connectionId);
await this.PublishAsync(message);
}RemoveFromGroupAsync, and the User-level commands all look very similar to this. What about message sending?
/// <inheritdoc />
public override Task SendGroupsAsync(
IReadOnlyList<string> groupNames,
string methodName,
object?[] args,
CancellationToken cancellationToken = default)
{
if (groupNames == null)
{
throw new ArgumentNullException(nameof(groupNames));
}
var publishTasks = new List<Task>(groupNames.Count);
foreach (var groupName in groupNames)
{
if (!string.IsNullOrEmpty(groupName))
{
var payload = this._handler.WriteMethodInvocation(
groupName,
methodName,
args);
publishTasks.Add(this.PublishAsync(payload));
}
}
return Task.WhenAll(publishTasks);
}
private async Task PublishAsync(IStatement payload)
{
this._session.Execute(payload)
}Couldn’t be easier. What about receiving? Remember that StartSubscriberAsync?
public async Task StartSubscriberAsync(
TimeSpan interval,
int tolerance,
CancellationToken cancellationToken)
{
var tasks = new List<Task>(groupNames.Count);
while (true)
{
try
{
var payload = await this._handler.ReadIntervalAsync(
interval,
Math.Min(tolerance, skippedBeats));
var results = await this._session.ExecuteAsync(payload);
foreach (var result in results)
{
tasks.Add(this.ProcessMessageAsync(result));
}
await Task.Delay(interval, cancellationToken);
}
catch (CqlException e)
{
this._logger.LogError(e, "An exception was encountered when reading");
this._skippedBeats += 1;
}
}
}Where ProcessMessageAsync parses through the various results and calls the appropriate routing methods. So that leaves one last part - if this is all over a decentralized CQL compatible database, how do we ensure only the messages the user is submitting are actually ones they are supposed to and not on behalf of someone else? And that, is where we start our next article: The Triple-Ratchet Algorithm. Merry Christmas!

Cassie Heart is the creator of Code Wolfpack, BDFL of Howler, The Bit with a Byte, Resident Insomniac.